CorePlexML
Machine Learning de principio a fin
Todo el ciclo de ML en una plataforma integrada.
Subes un archivo y el AI Builder (un LangGraph agent sobre LLM) te guía para preparar el dataset: detección de tipos, limpieza, encoding, feature engineering, todo conversacional. Lanzas un experimento y H2O.ai + FLAML compiten en paralelo evaluando GBM, XGBoost, DeepLearning, RandomForest, GLM y más. En 4 minutos tienes el mejor modelo con métricas, variable importance y SHAP analysis. Lo despliegas con un click y tienes una API REST de predicción con monitoreo de drift, alertas y A/B testing automático.
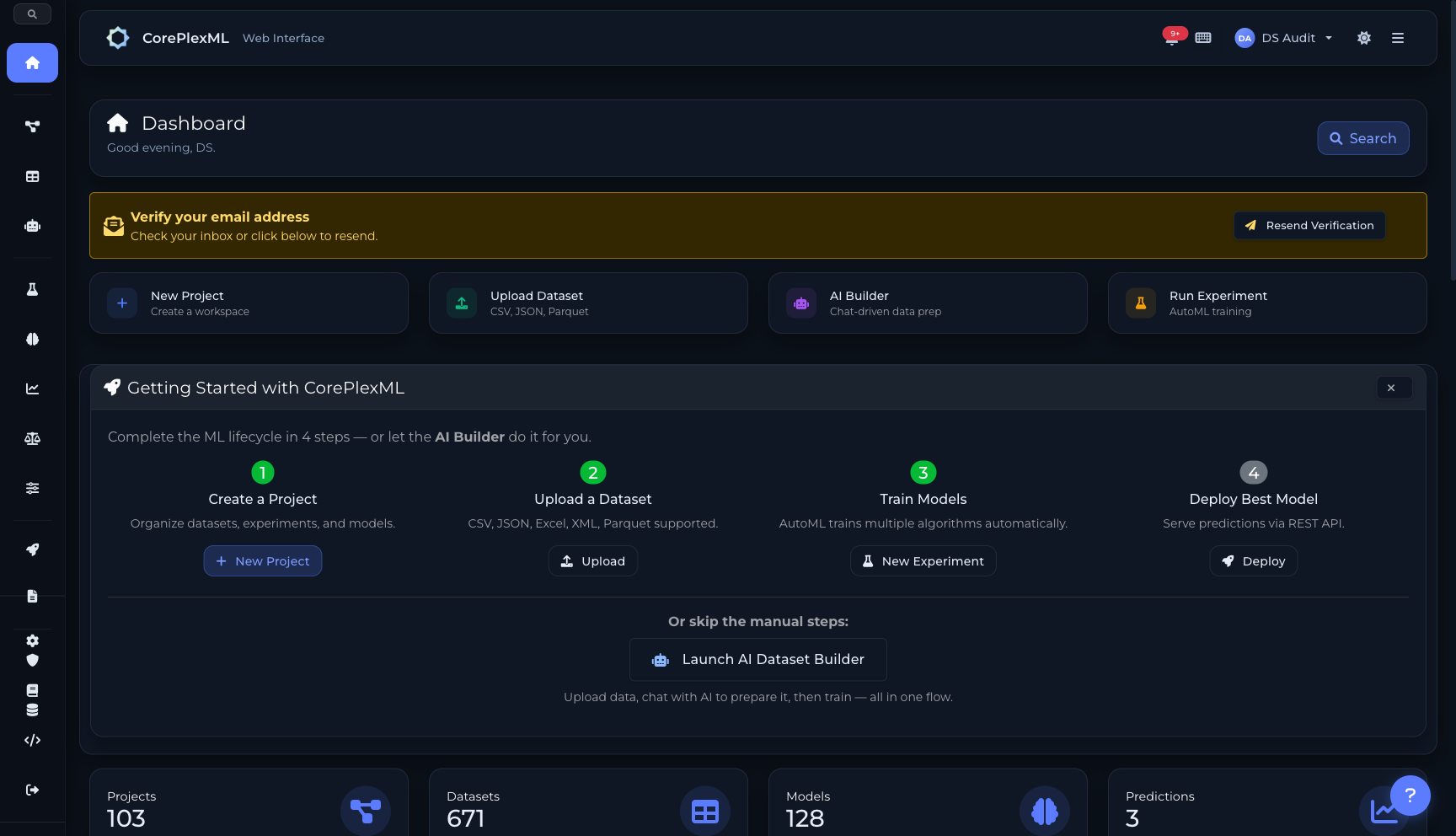
Dashboard principal con proyectos, datasets, modelos, deployments y métricas
AutoML multi-engine
Dos motores compitiendo en paralelo
H2O.ai y FLAML ejecutan simultáneamente, evaluando 23+ algoritmos (GBM, XGBoost, DeepLearning, RandomForest, GLM, StackedEnsemble, LightGBM, ExtraTrees y más). El mejor modelo se selecciona automáticamente comparando AUC, RMSE, LogLoss o la métrica que definas. Soporte para clasificación binaria, multiclase, regresión y series temporales. En 4 minutos tienes el leaderboard completo con el ganador seleccionado.
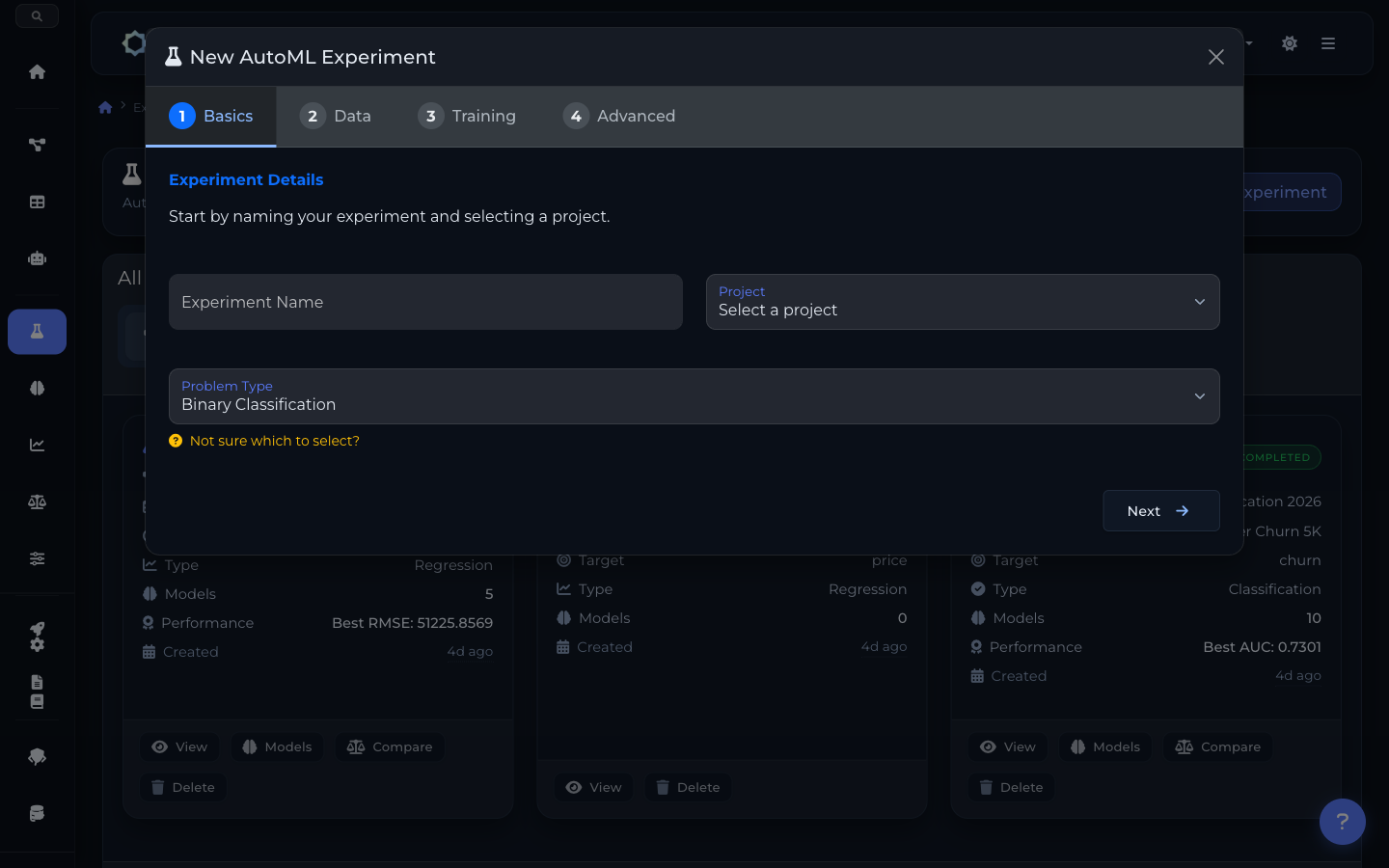
Wizard de configuración: selección de proyecto, dataset, target y tipo de problema
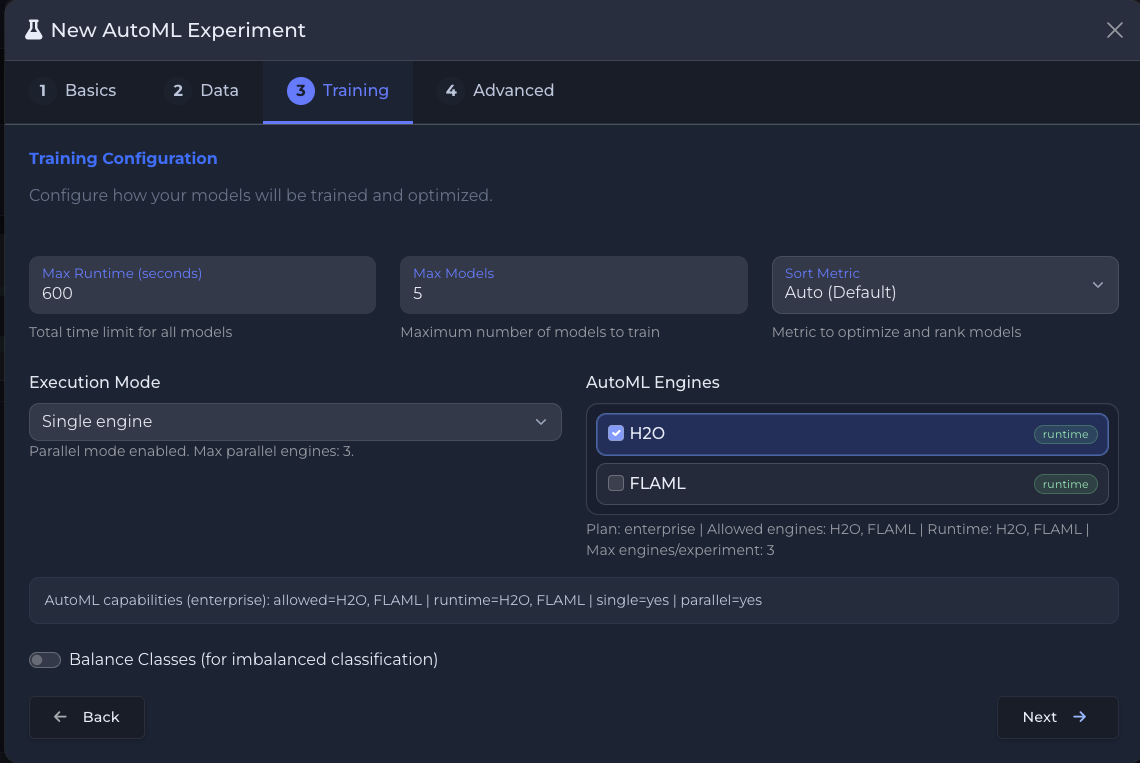
H2O.ai y FLAML ejecutando en paralelo con leaderboard en tiempo real
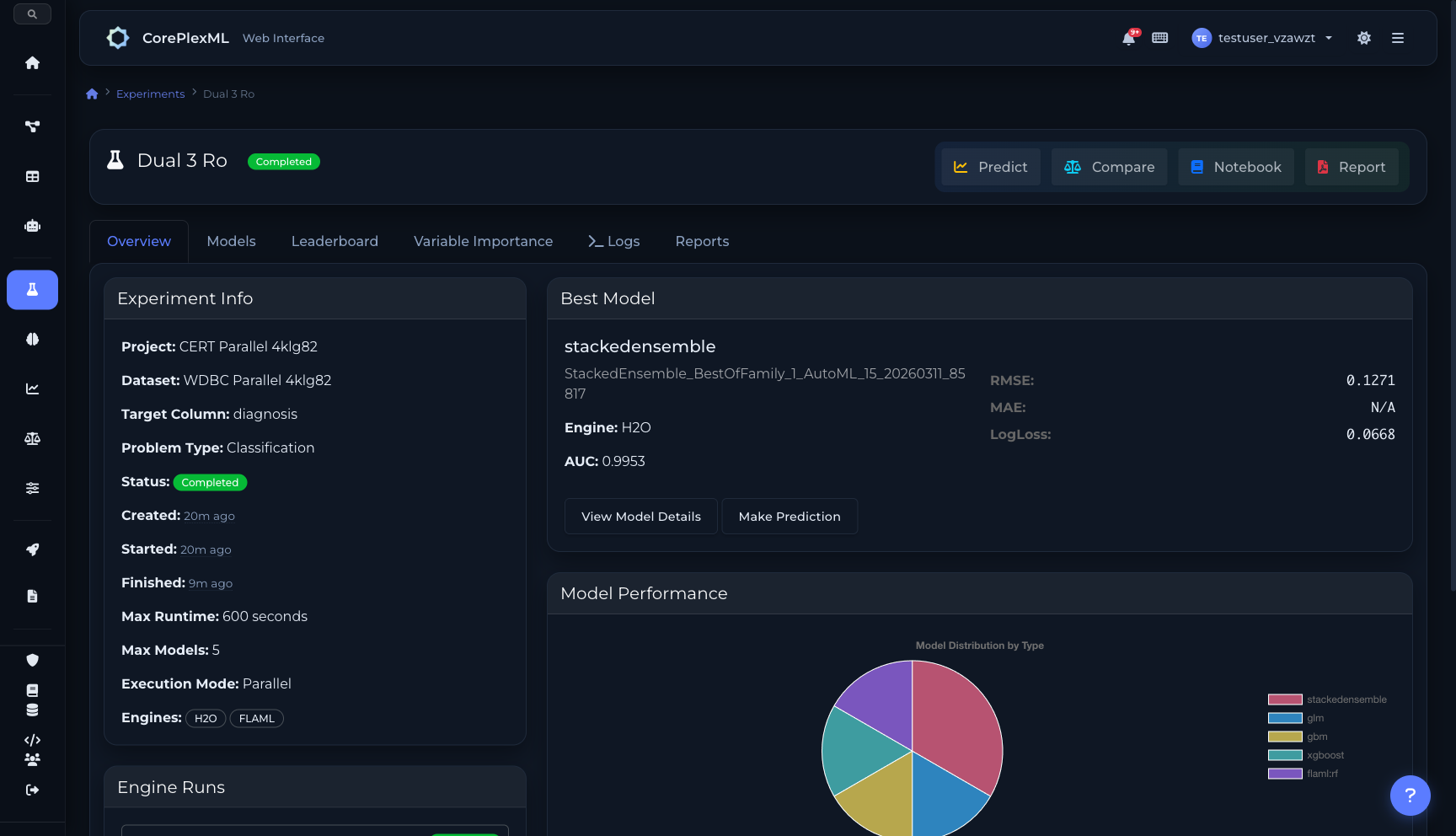
Parallel overview
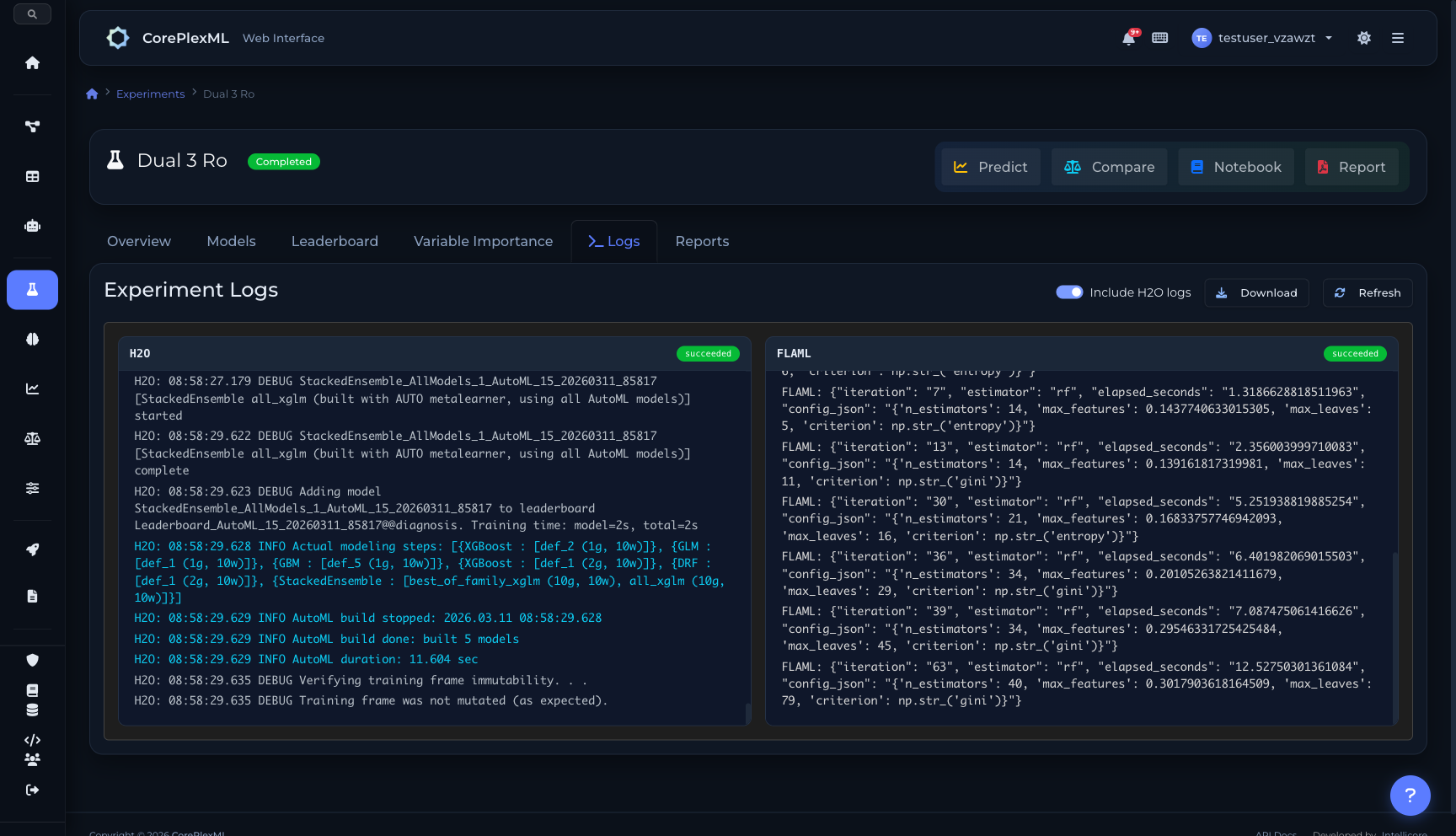
Dual engine logs
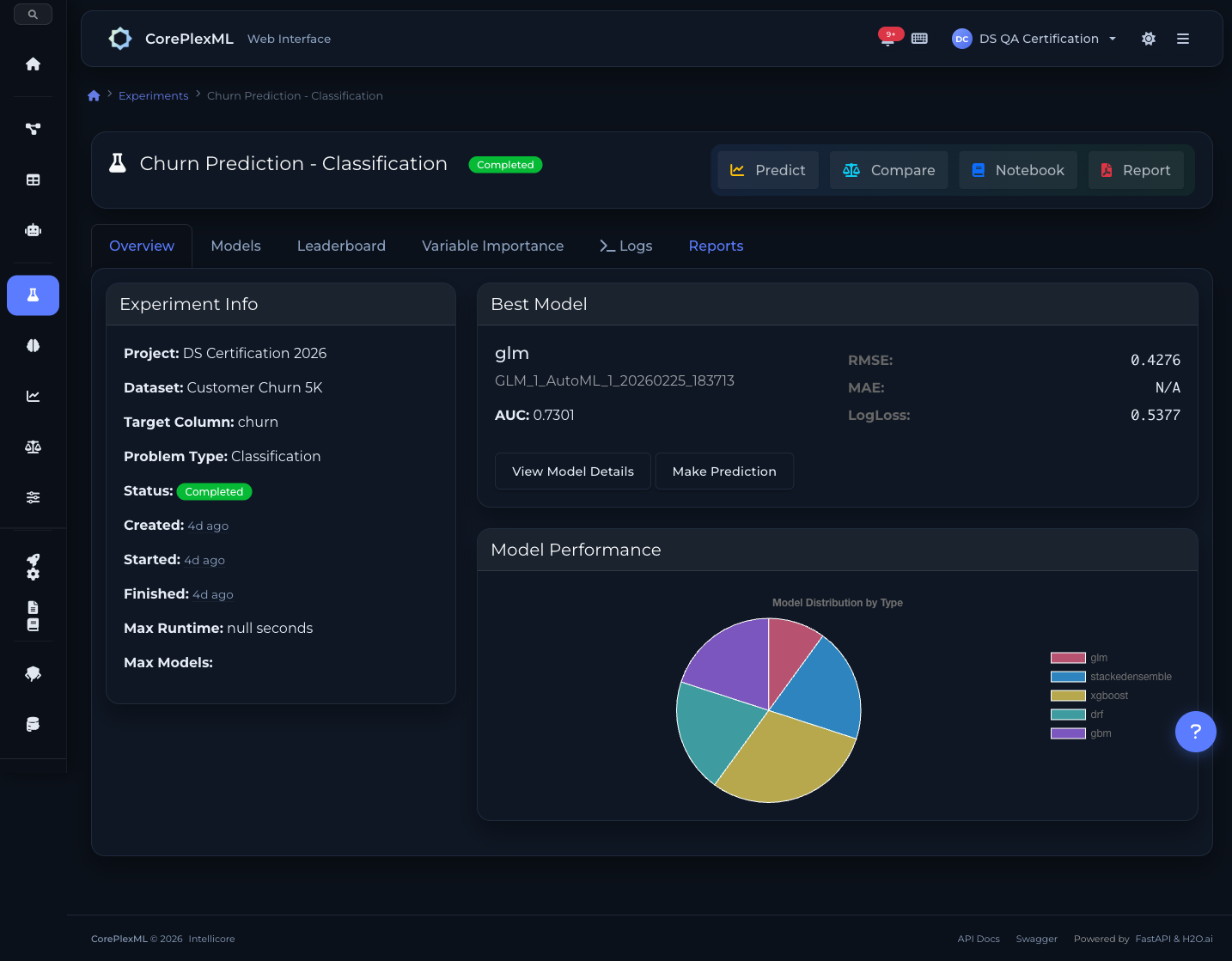
Experiment overview
Dataset Builder AI
Preparación de datos conversacional
Sube un CSV, JSON, Excel, XML o Parquet. El AI Builder (un agente LangGraph sobre Claude) analiza el dataset, detecta tipos, identifica problemas de calidad, y te guía paso a paso: limpieza, encoding de categóricas, feature engineering, manejo de valores faltantes. Todo conversacional: le dices qué quieres hacer y él ejecuta los scripts de transformación.
Data Quality Gate integrado: cada dataset pasa por validación automática con scoring de calidad. Si hay problemas, los reporta antes de que entrenes un modelo con datos malos.
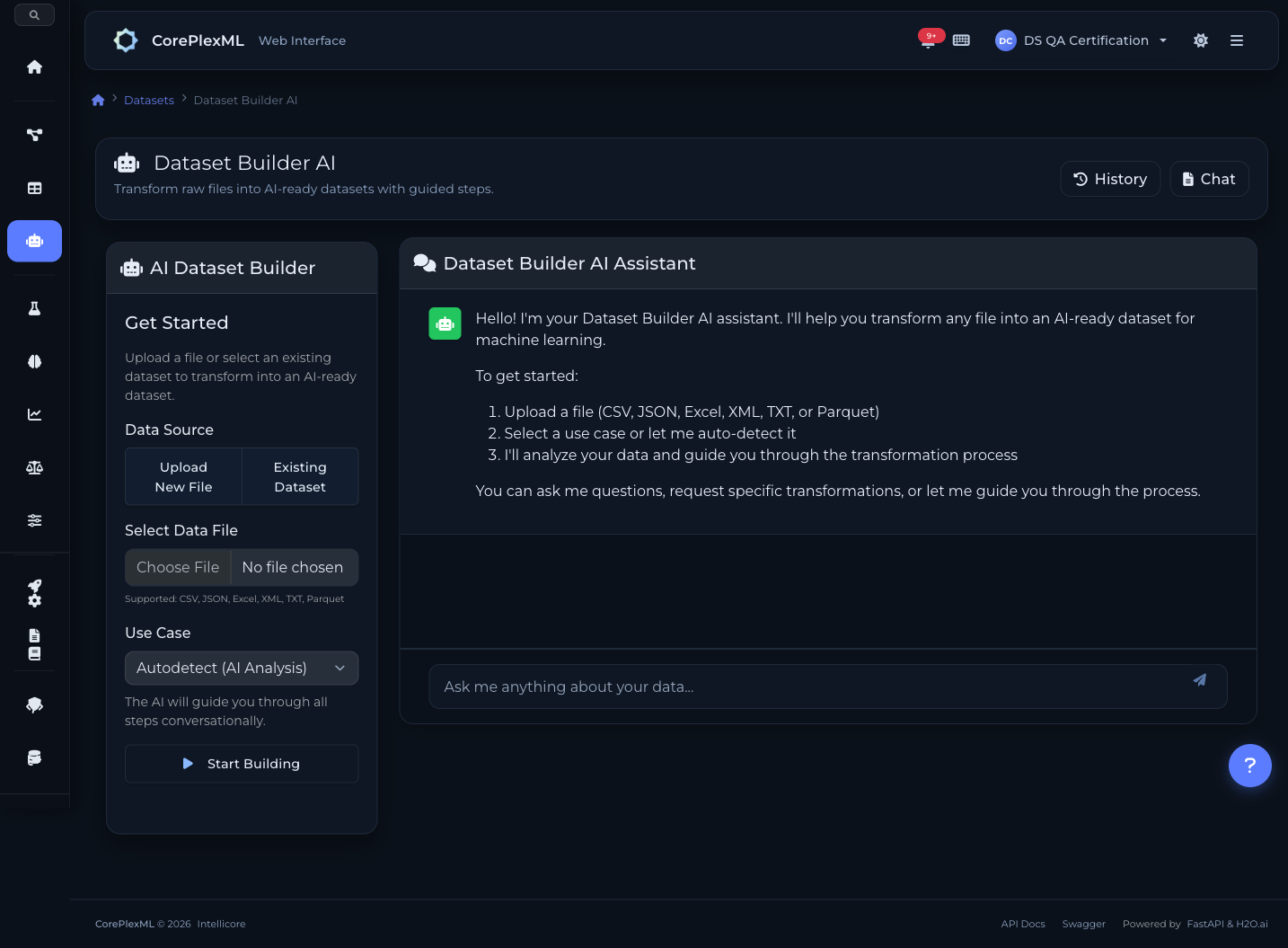
Dataset Builder AI
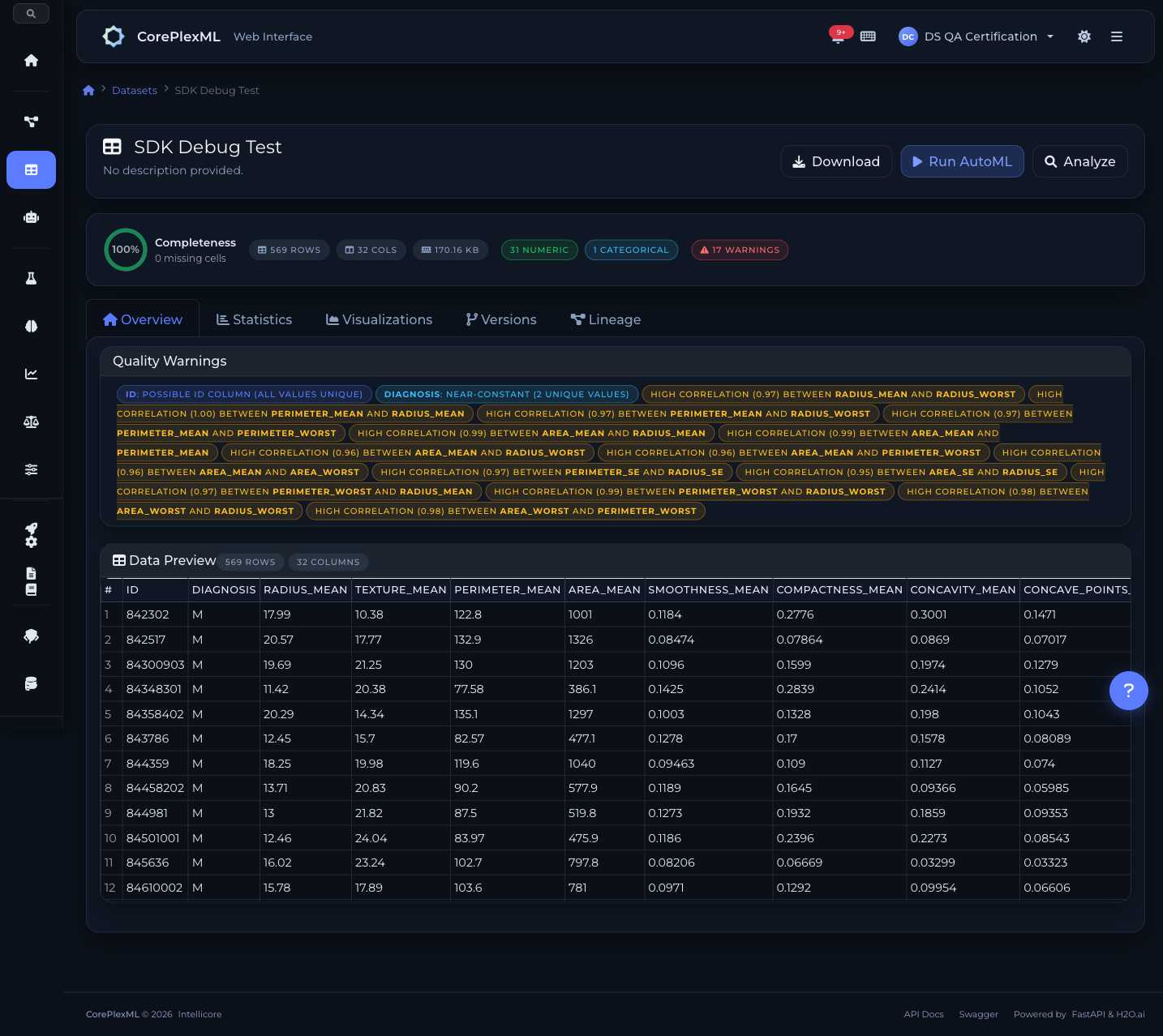
Dataset overview
Modelos y explicabilidad
Entender por qué el modelo decide lo que decide
SHAP analysis para entender la contribución de cada feature a cada predicción. Variable importance global. Partial Dependence Plots para relaciones no lineales. Learning curves para diagnosticar overfitting. Comparación side-by-side de múltiples modelos con métricas, curvas y contribuciones. Gains/Lift charts para evaluar performance en deciles.
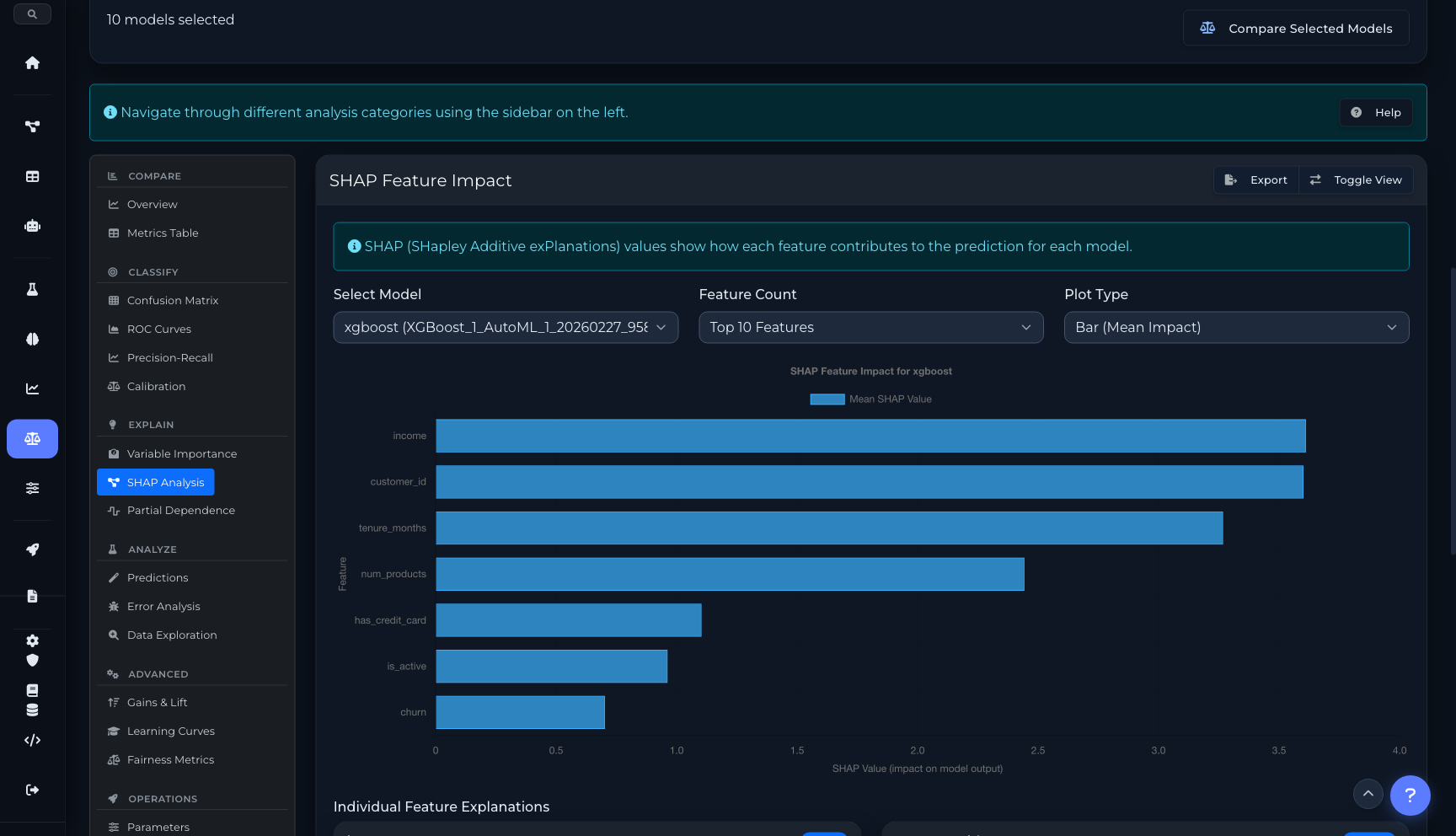
Contribución de cada feature a las predicciones del modelo, explicabilidad global
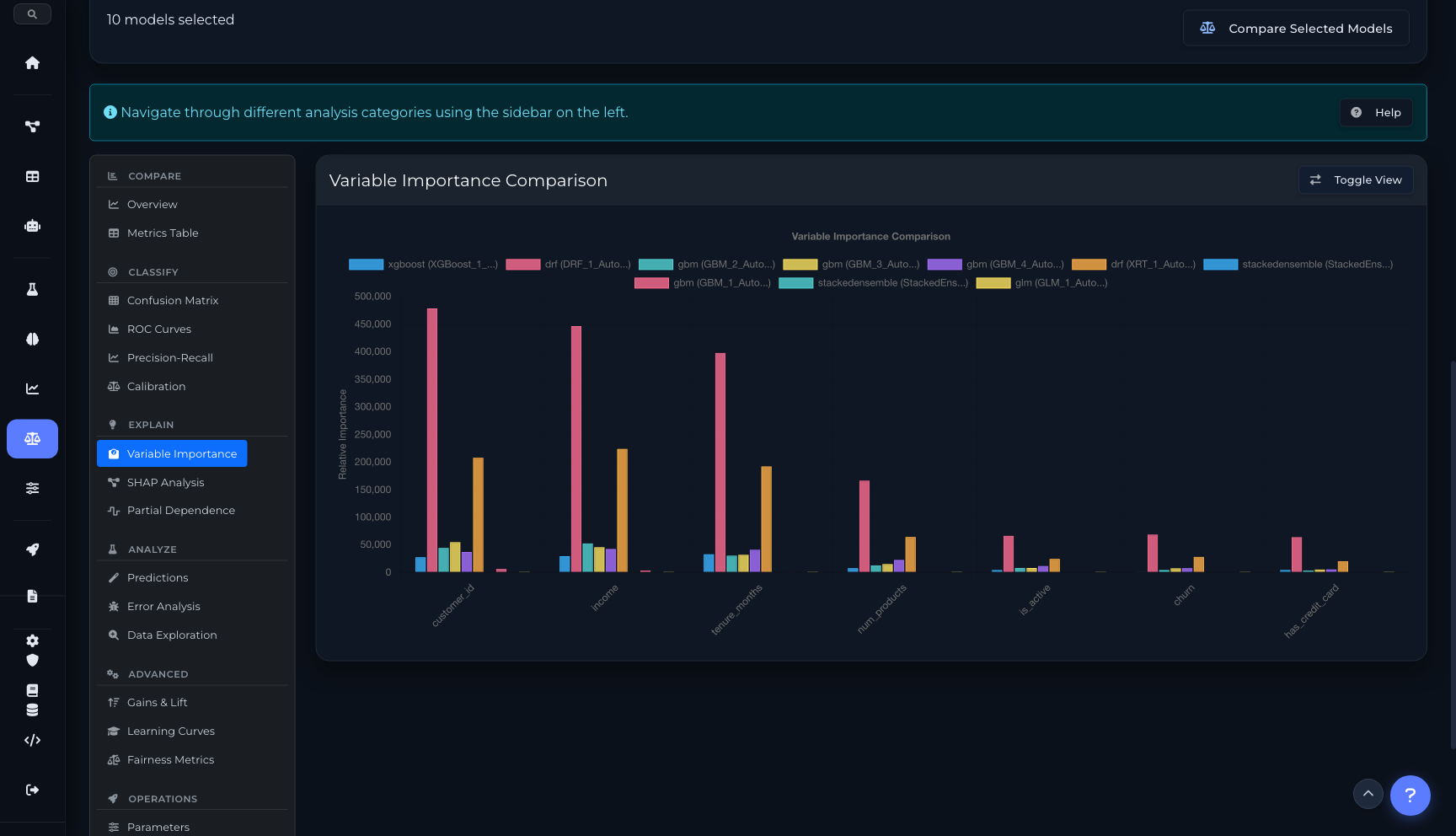
Variable Importance
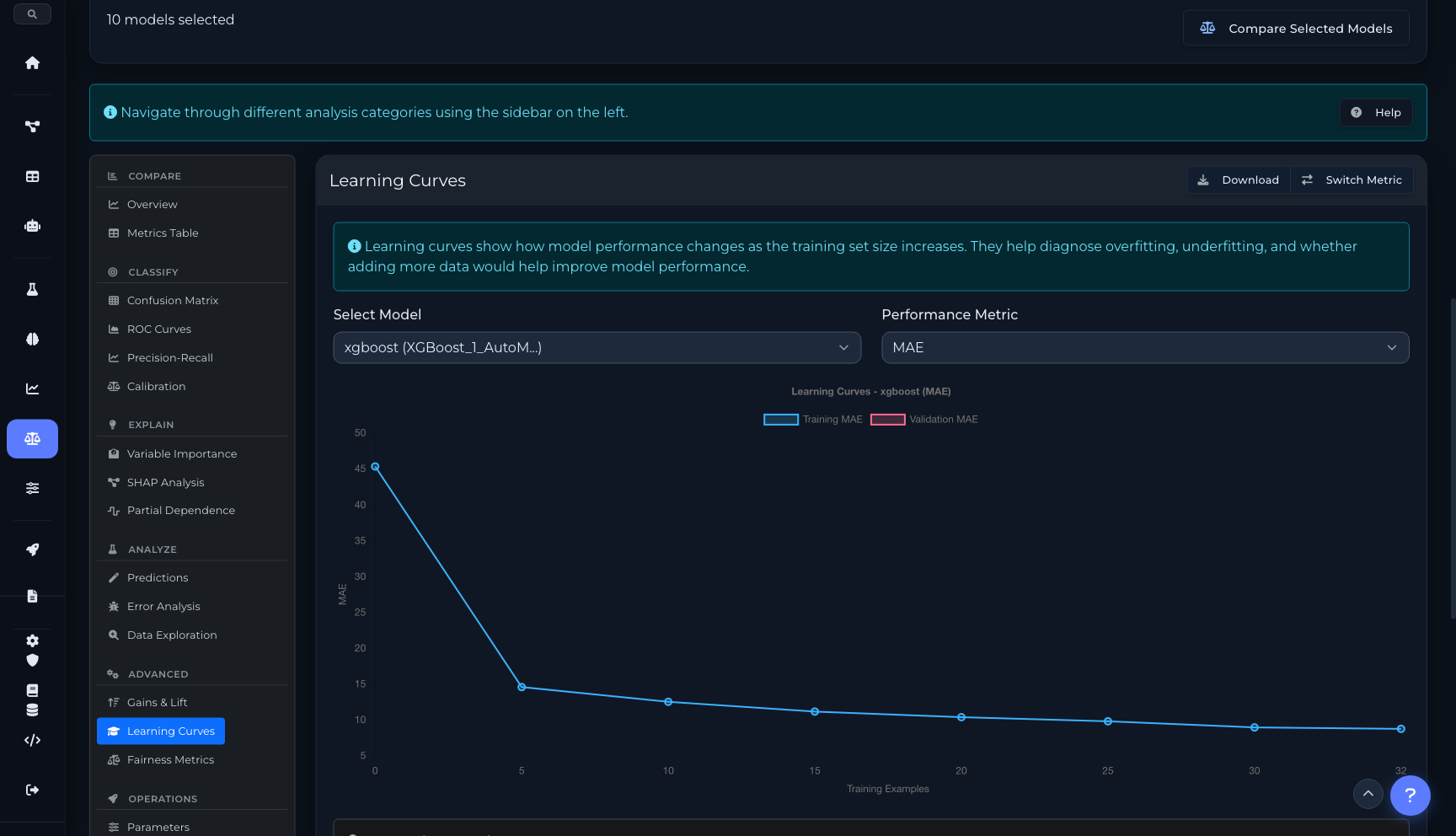
Learning Curves
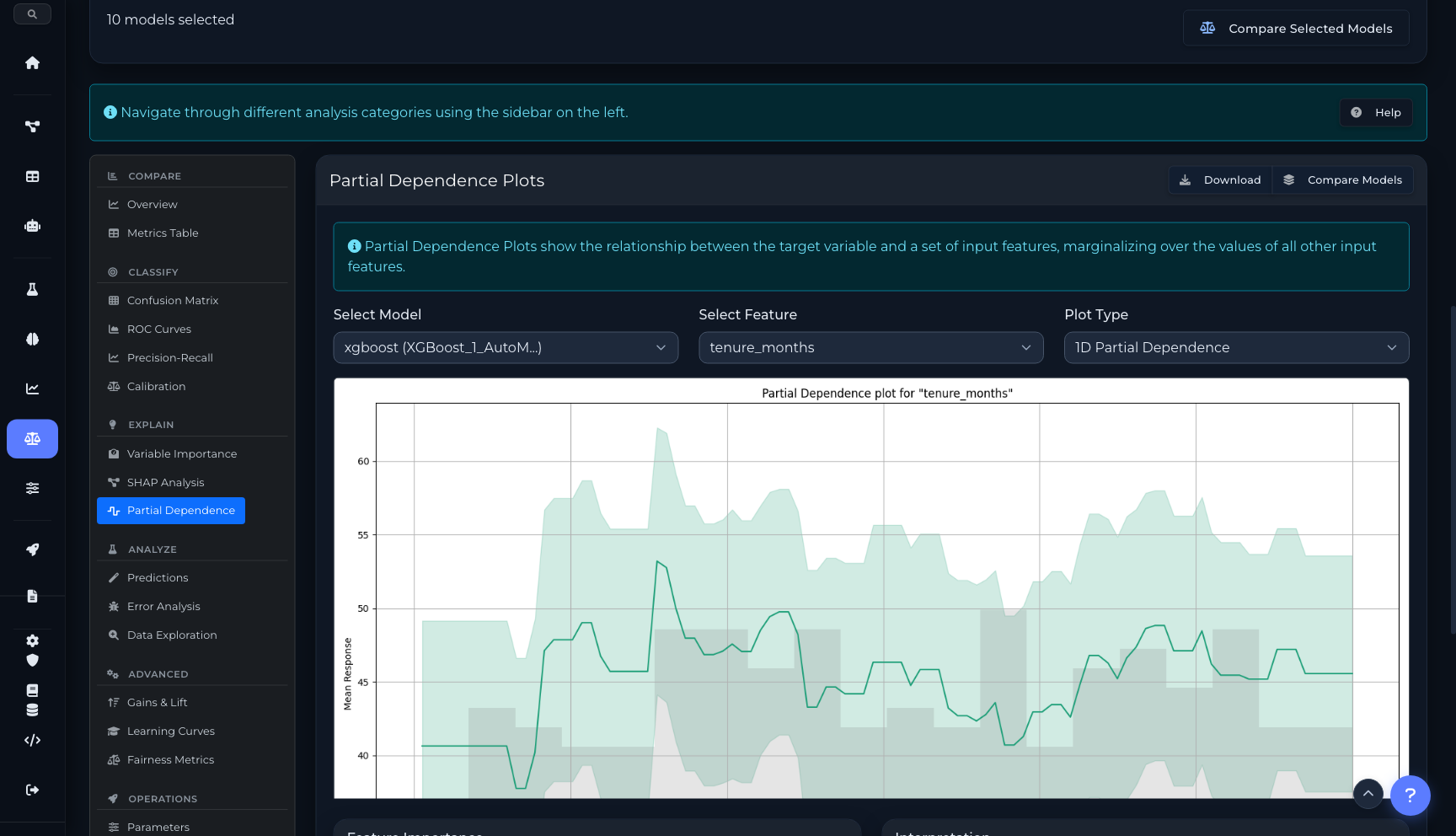
Partial Dependence
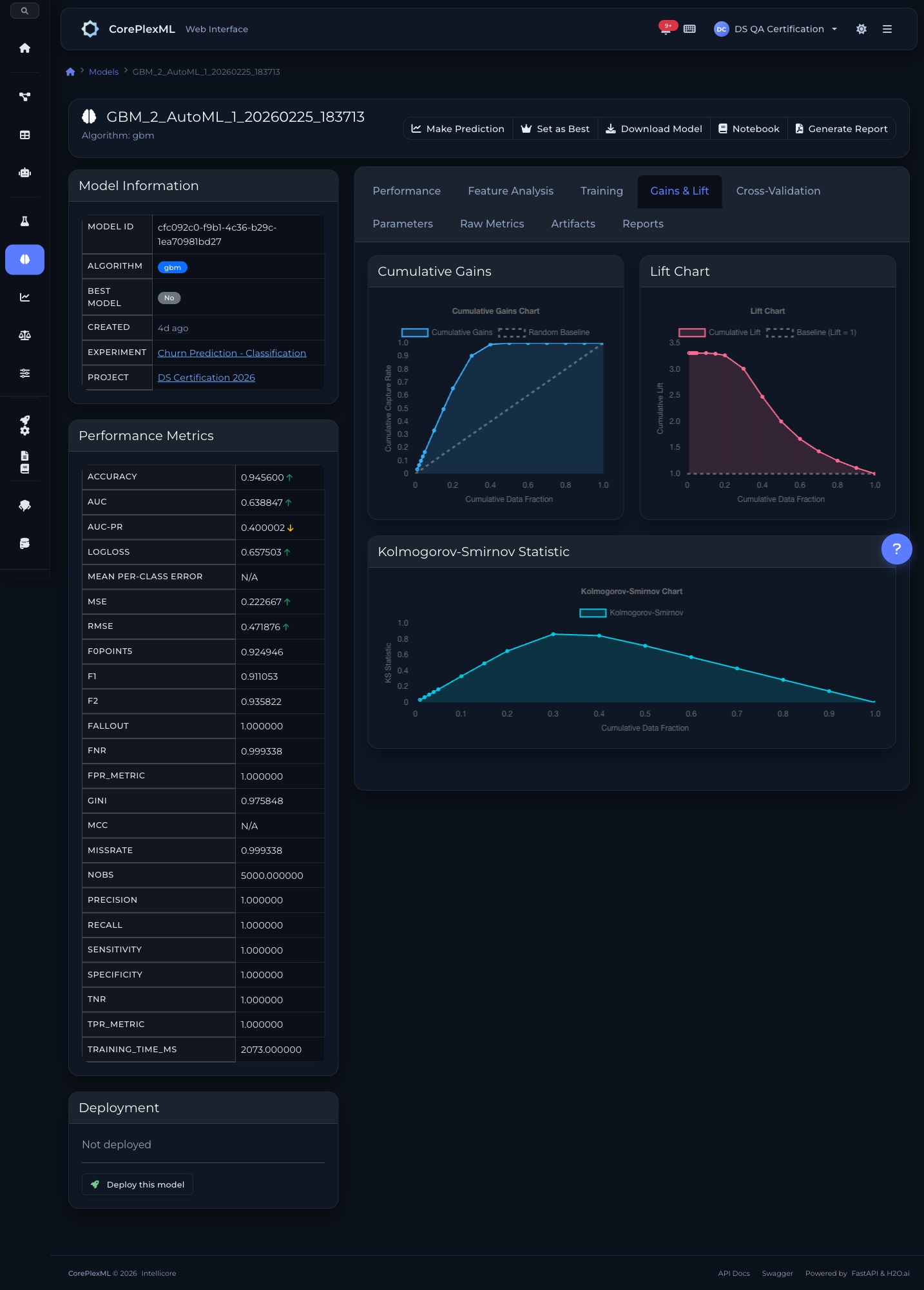
Gains/Lift
MLOps
Del modelo al endpoint de predicción con un click
Deploy con canary strategy (10% → 50% → 100%). API REST de predicción instantánea. Monitoreo de drift con SHAP feature importance, detecta cuando el modelo empieza a degradar antes de que afecte a los usuarios. Alertas configurables via Slack + email. A/B testing automático entre modelos. Auto-retraining cuando la performance baja del umbral definido.
Model Registry con versionado y stages (development, staging, production). Batch predictions para scoring masivo. Reports PDF auto-generados con métricas y recomendaciones.
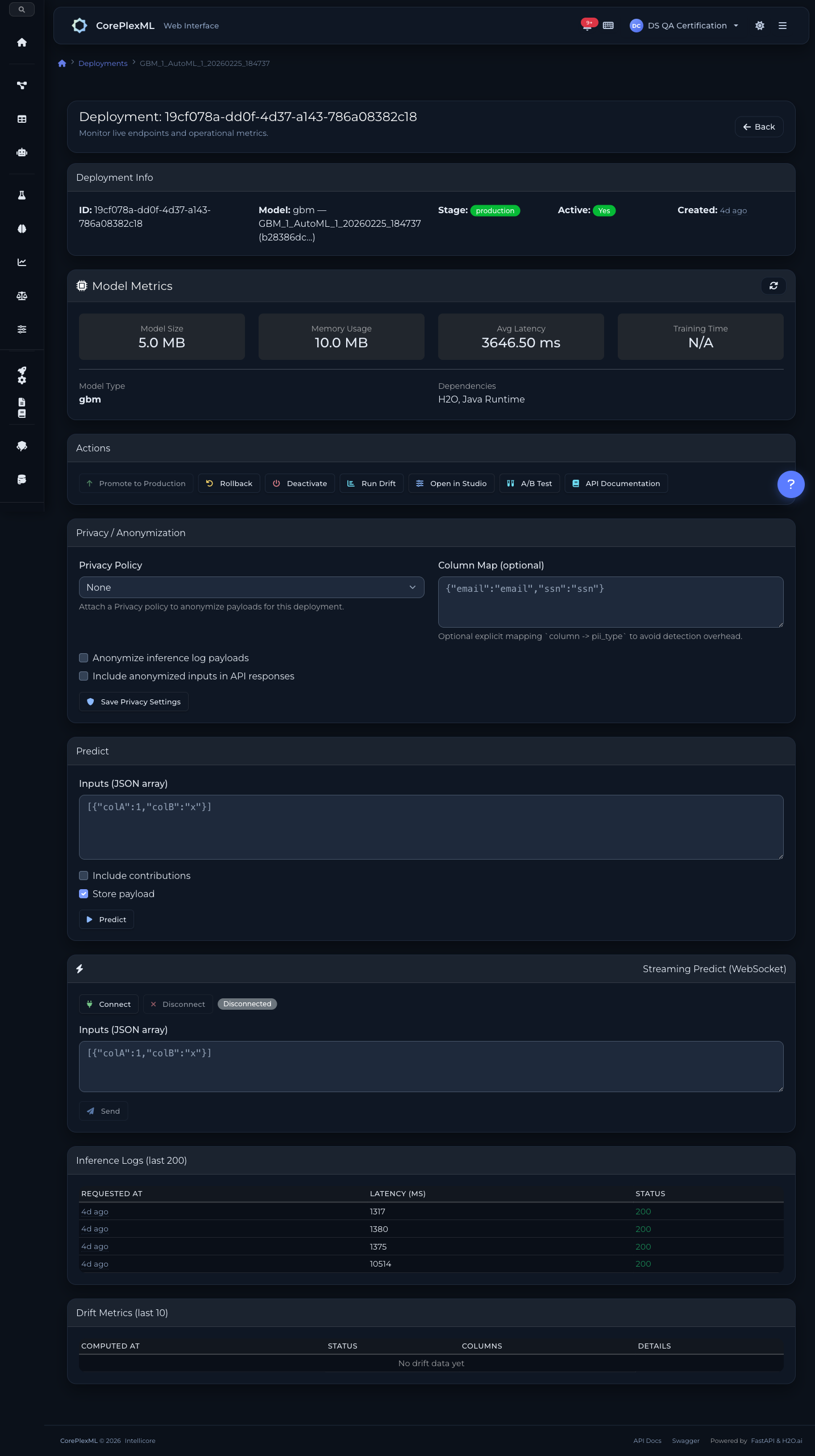
Modelo desplegado con endpoint REST, métricas de uso y configuración de monitoreo
Deployments list
Model Registry
Alert Rules
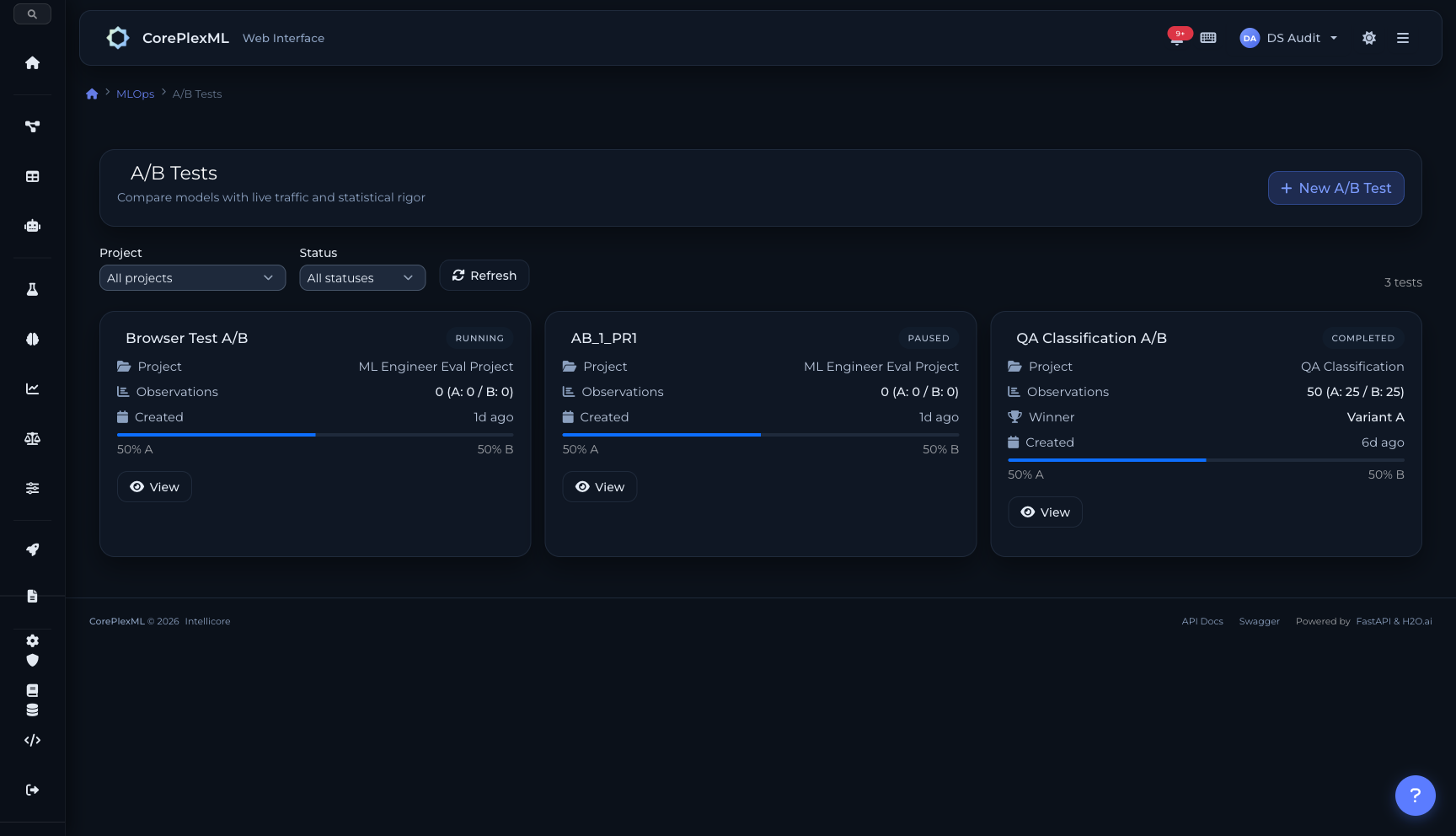
A/B Test Results
Enterprise Features
Privacy Suite
55+ detectores de PII combinando regex patterns con NLP extraction. Perfiles pre-configurados: GDPR, HIPAA, PCI-DSS, CCPA. Detecta emails, teléfonos, SSN, tarjetas de crédito, direcciones, fechas de nacimiento, IBANs, direcciones IP, coordenadas GPS y más. Transformaciones reversibles (pseudonymize con vault) e irreversibles (hash, mask, redact). Cada operación queda en un audit log inmutable.
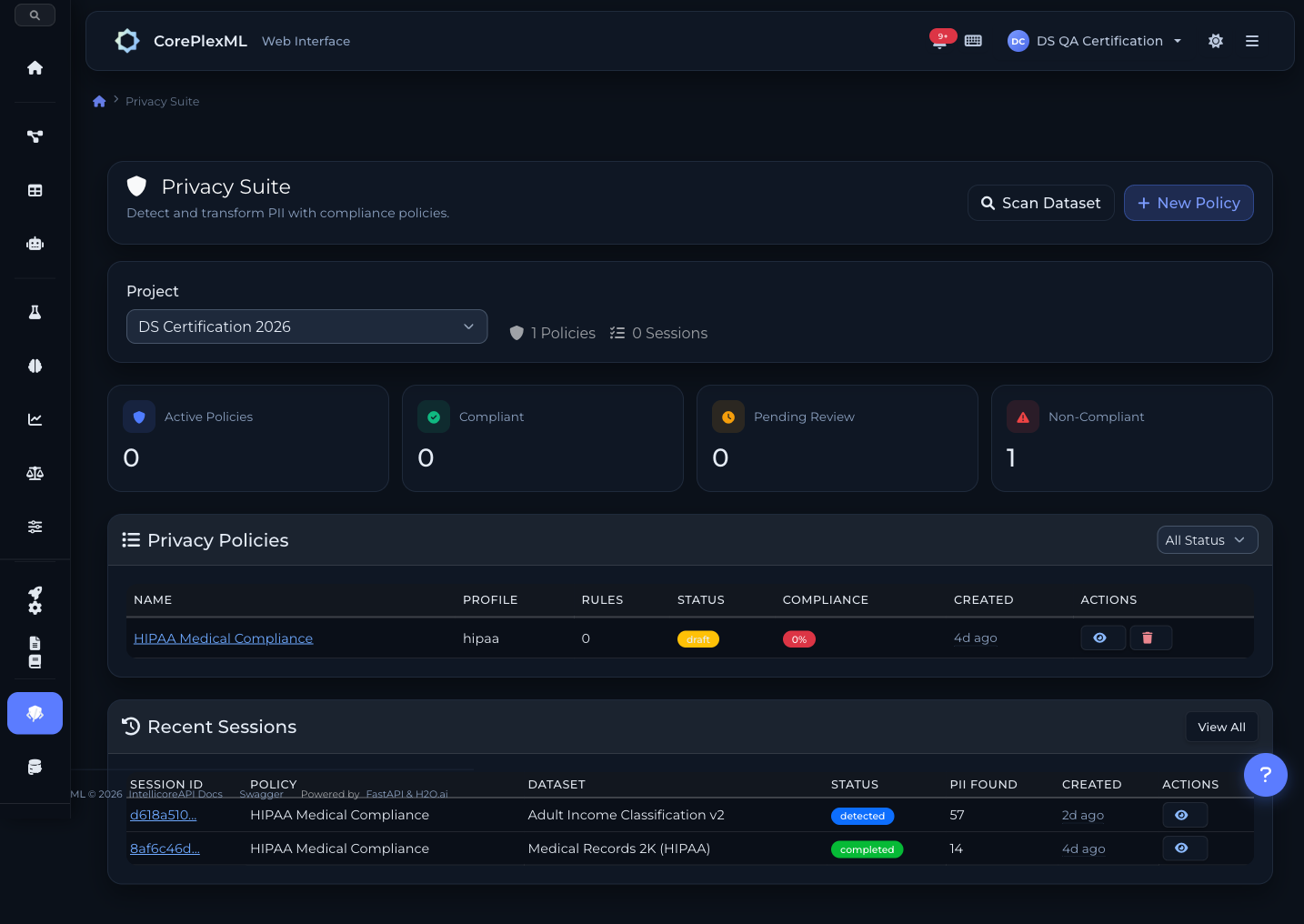
Detección de PII con perfiles GDPR/HIPAA y transformaciones configurables
What-If Studio
Análisis de escenarios interactivo. Selecciona un deployment, define un baseline, y crea escenarios alternativos cambiando features individuales. Ve en tiempo real cómo cambia la predicción, con contribuciones SHAP por feature para entender el por qué. Comparación side-by-side de múltiples escenarios. Soporte para modelos de regresión y clasificación.
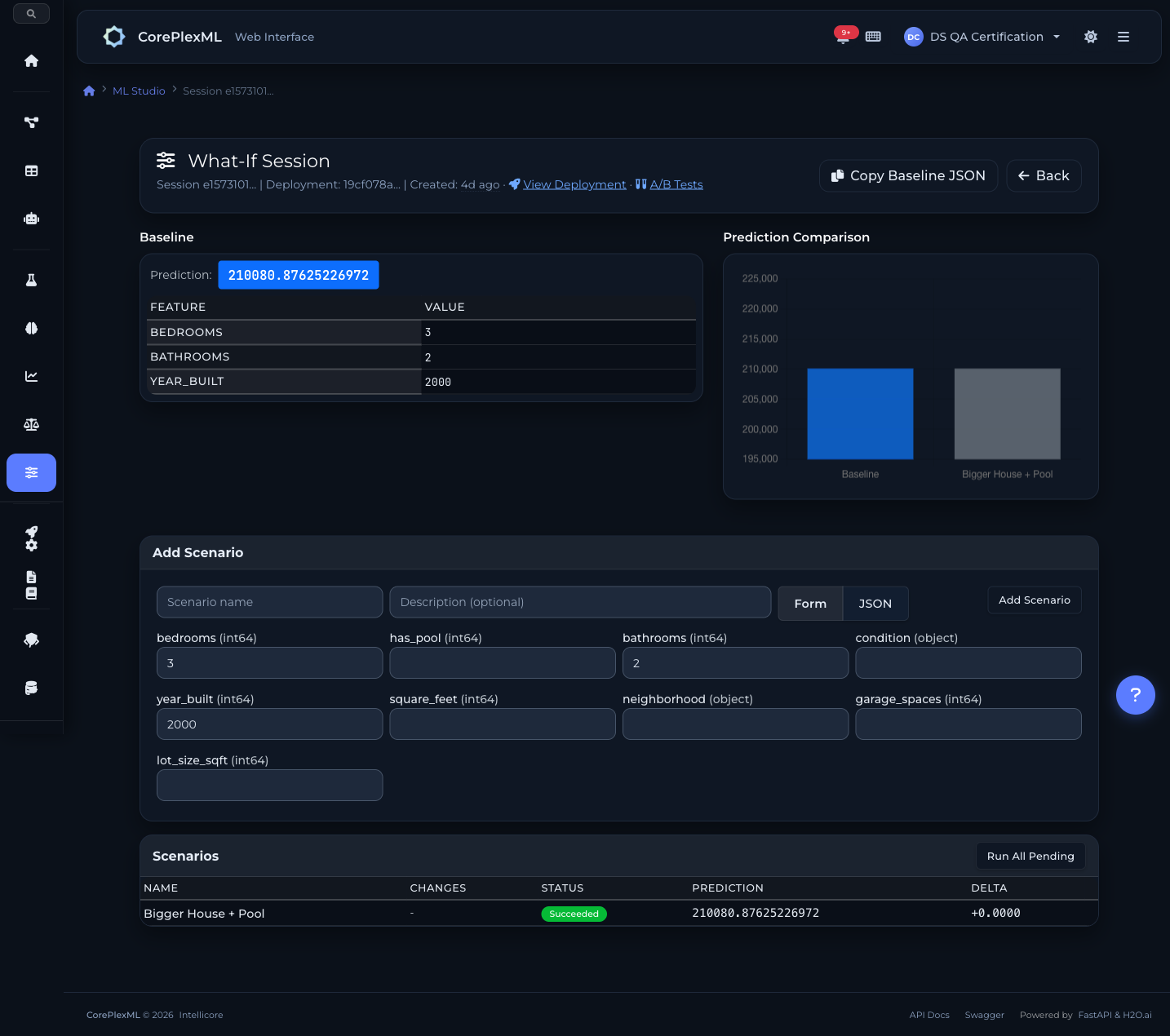
Análisis de escenarios: cambia features y ve el impacto en predicciones en tiempo real
SynthGen
Generación de datos sintéticos cuando los datos reales no alcanzan o no se pueden usar por compliance. Tres engines: CTGAN (Conditional Tabular GAN), CopulaGAN, y TVAE. Preserva distribuciones estadísticas del dataset original. NDJSON streaming para datasets grandes. Evaluación automática de calidad de los datos generados vs. originales.
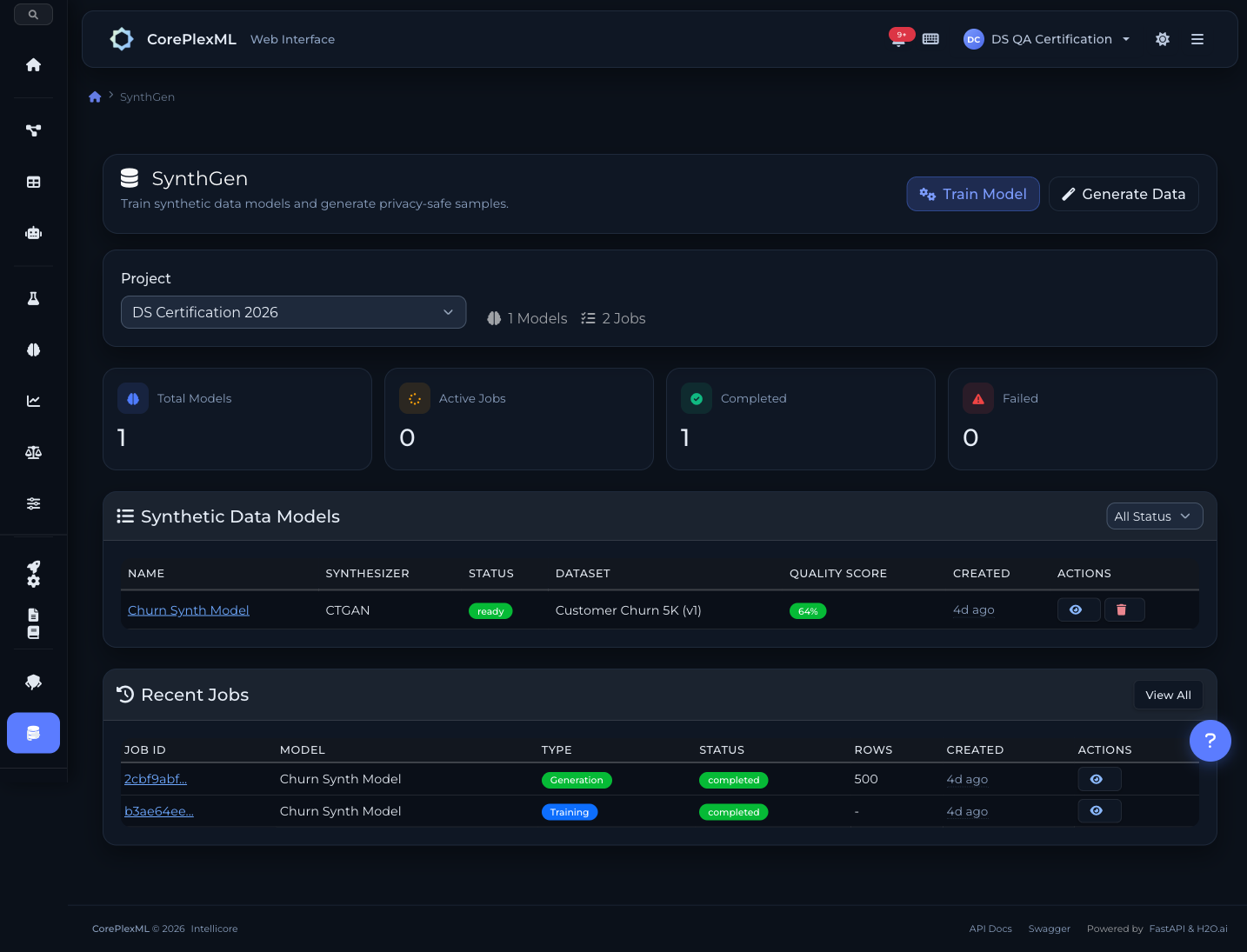
Generación de datos sintéticos con CTGAN preservando distribuciones estadísticas
Certificación
Certificada para producción enterprise
CorePlexML pasó por 12 gates de certificación independientes: paridad triple UI/API/DB, visual stress con Playwright, auditoría semántica, y certificación de componentes absoluta. Cada gate simula un perfil técnico distinto intentando encontrar problemas. Resultado: cero bloqueantes funcionales.
$ cert-runner --all-gates
│
PASS ml_engineer_meta 85/85
PASS triple_parity 71/71
PASS ui_component 52/52
PASS playwright_stress 34/34
PASS studio_stress 48/48
PASS synthgen_streaming 21/21
PASS multi_automl 11/11
PASS builder_stress 32/32
PASS data_parity 14/14
PASS semantic_audit 19/19
PASS ui_api_parity 49/49
PASS platform_complete 126/126
│
562/562 · Decisión: GO
Resultado completo
12 gates independientes ejecutados sobre stack live. Cada gate con su perfil de calidad específico.
Planes
Desde exploración hasta enterprise
CorePlexML está disponible como SaaS en coreplexml.io con cuatro planes que escalan según la necesidad de tu equipo. Todos los planes incluyen el pipeline completo: Dataset Builder AI, AutoML, modelos con explicabilidad SHAP, MLOps y reportes.
Free
1 proyecto
AutoML con H2O
Dataset Builder AI
Modelos con SHAP
MLOps básico (1 deployment)
Reportes
Pro
5 proyectos
AutoML multi-engine (H2O + FLAML)
Privacy Suite (GDPR, HIPAA, PCI-DSS)
SynthGen (datos sintéticos)
What-If Studio
MLOps completo + alertas
Soporte prioritario
Team
Proyectos ilimitados
Todo en Pro
Hasta 10 usuarios
Roles y permisos por equipo
A/B testing entre modelos
Auto-retraining
Soporte dedicado
Enterprise
Usuarios ilimitados
Todo en Team
Instalación on-premise (Docker)
SSO / SAML
SLA personalizado
Capacitación presencial
Soporte 24/7
Planes anuales disponibles con descuento. Todos los precios en USD.
Para quién sirve
Equipos de datos que necesitan una plataforma integrada sin fragmentar en Jupyter + MLflow + Airflow + scripts custom. Empresas que quieren ML en producción sin un PhD en cada reunión. CDOs que necesitan compliance built-in (GDPR/HIPAA), no bolted-on.
Qué resuelve
Fragmentación de herramientas. Modelos que nunca llegan a producción. Falta de reproducibilidad. Compliance como afterthought. Drift silencioso que degrada predicciones sin que nadie se entere. Notebooks de Jupyter que no se pueden deployear.
Modalidad
SaaS en coreplexml.io o implementación dedicada On-Premise (Docker Compose, ~3.9GB image, PostgreSQL, CPU-only). Licencia anual para Enterprise. Incluye soporte técnico y actualizaciones.
Implementa CorePlexML en
tu organización.
Del CSV al modelo en producción. SaaS o On-Premise. SDK en Python. Certificada para enterprise.